Use Case
The primary use case for completion datasets is to provide developers with high-quality data for the finetuning of LLMs. By leveraging curated data derived from traces, developers can enhance the accuracy, relevance, and effectiveness of their LLMs across various applications and use cases.Key Features
- Curated Data: Completion datasets are curated from traces to ensure relevance and quality, providing developers with reliable data for finetuning their LLMs.
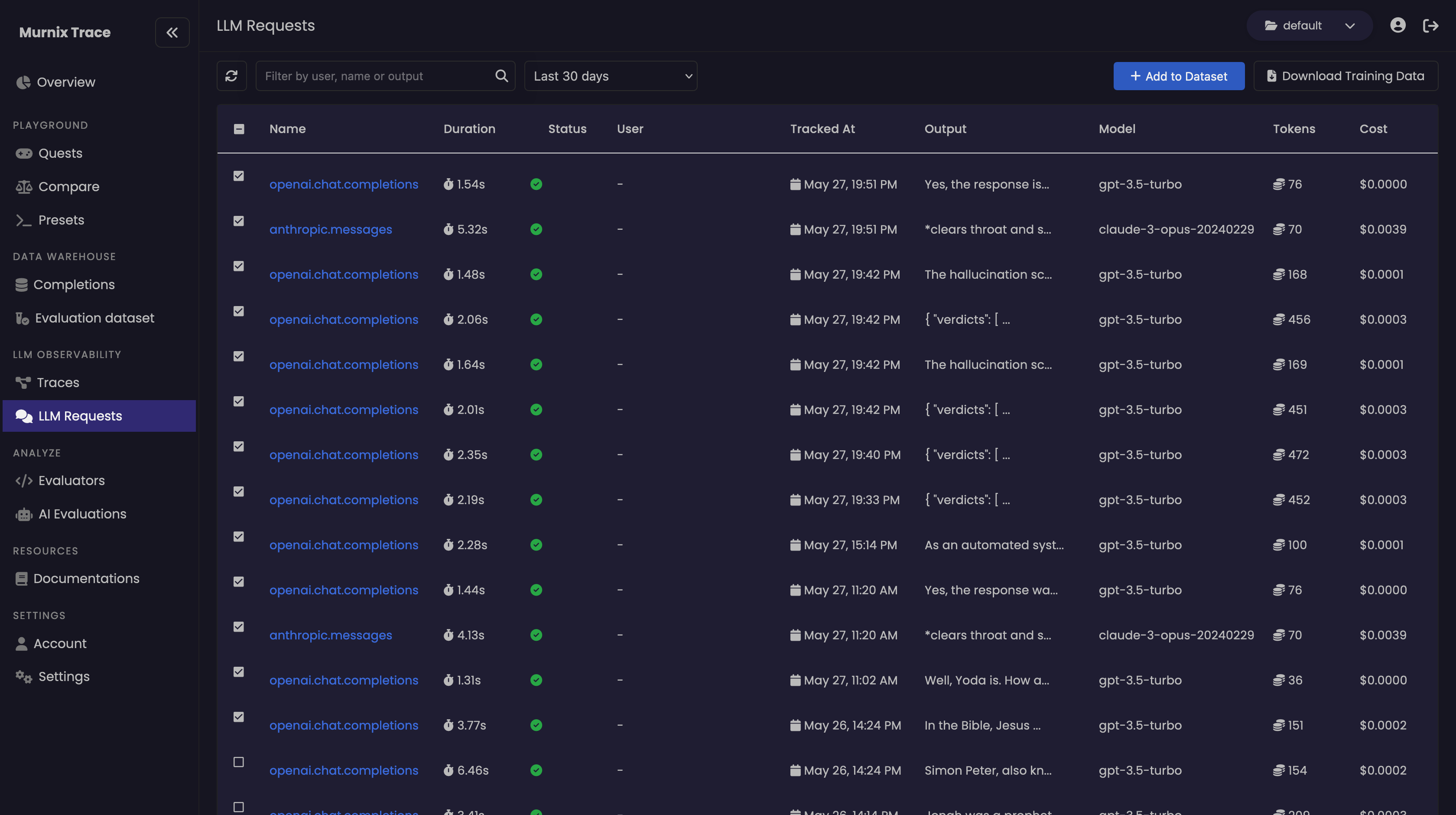
- Dataset Groups: Murnitur AI allows developers to organize completion datasets into dataset groups for bulk downloading or evaluations. This streamlines the process of managing and accessing datasets for finetuning purposes.
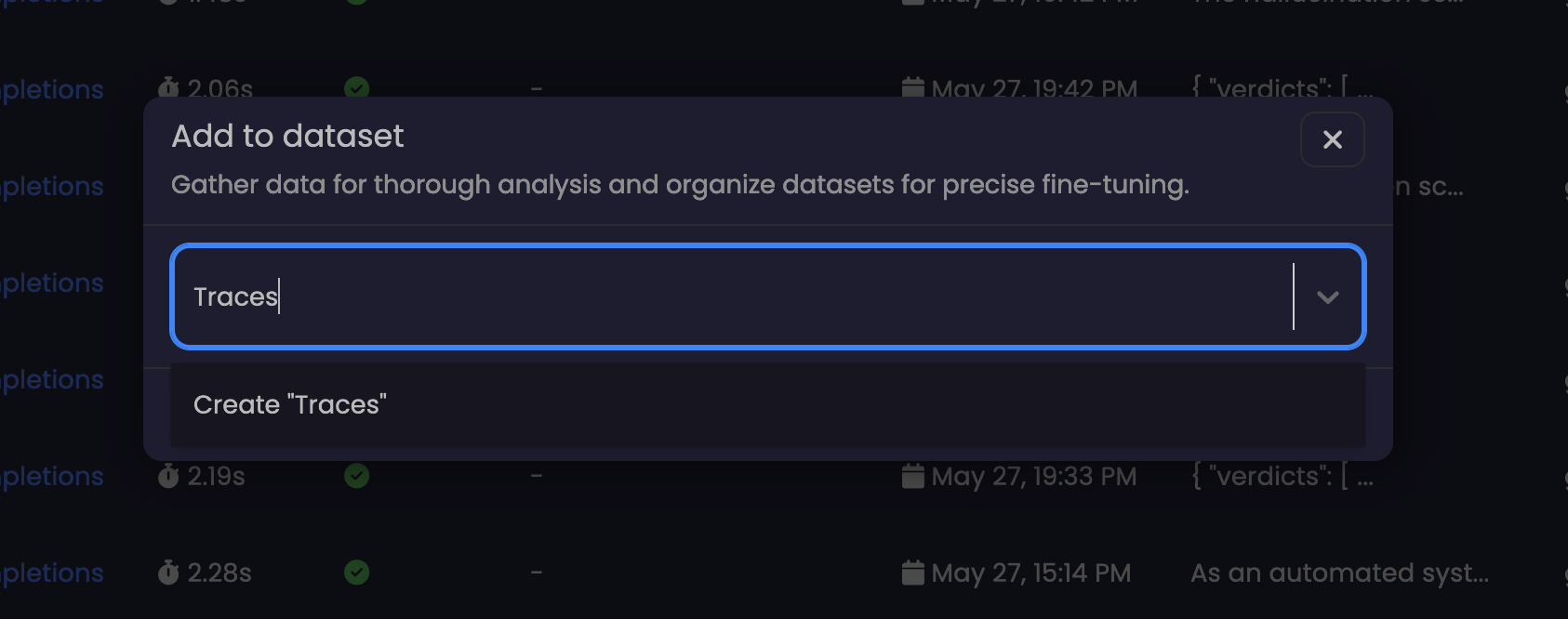
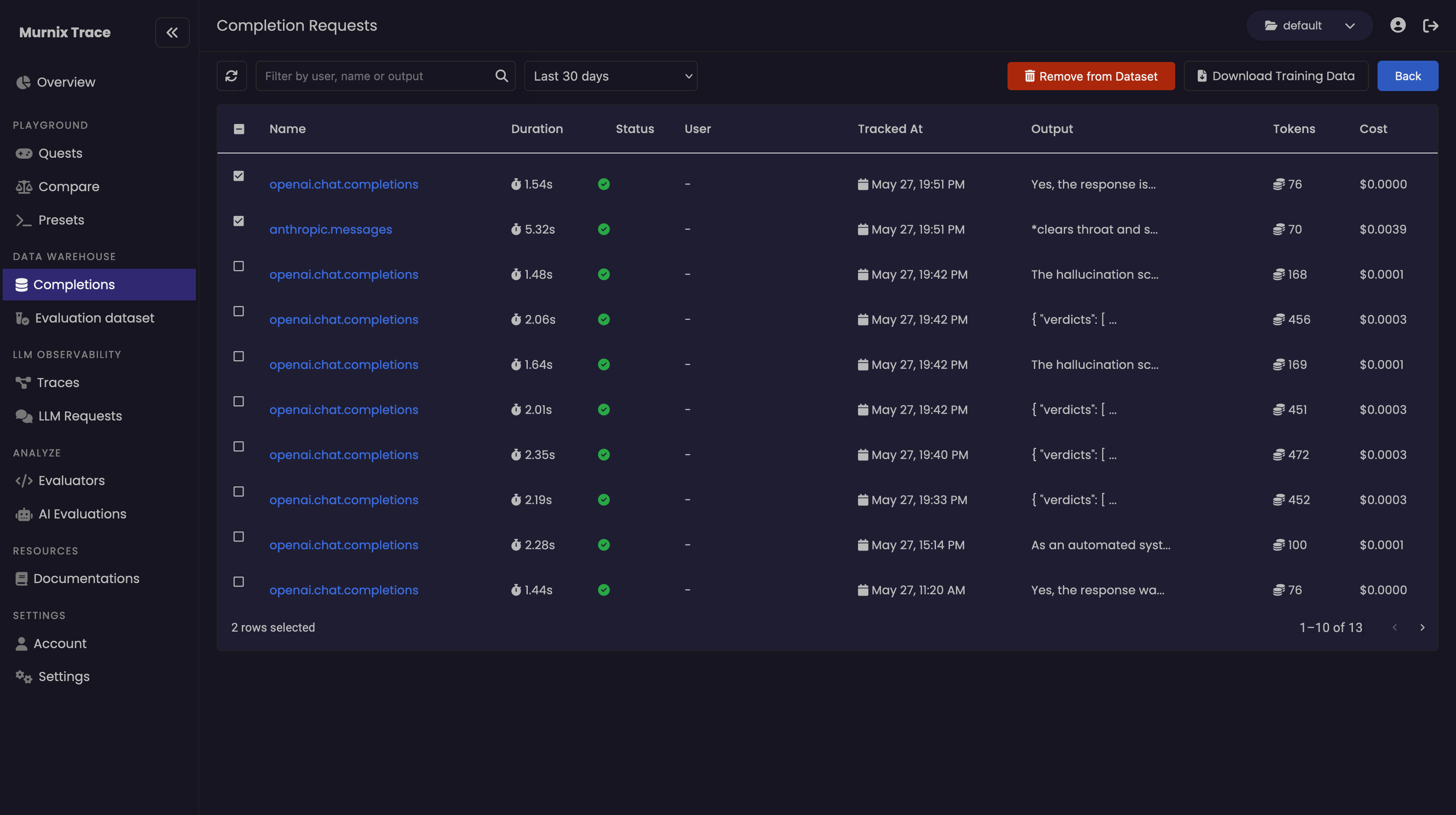
- Download Options: Developers have the option to download completion datasets directly for use in finetuning their LLMs.
Benefits
- Enhanced Performance: By leveraging curated completion datasets, developers can enhance the performance and accuracy of their LLMs through finetuning.
- Time Savings: Curated completion datasets save developers time by providing pre-selected, high-quality data for finetuning, eliminating the need to manually curate datasets.
- Improved Relevance: Completion datasets derived from traces ensure relevance to specific use cases, resulting in more effective finetuning of LLMs tailored to particular applications.