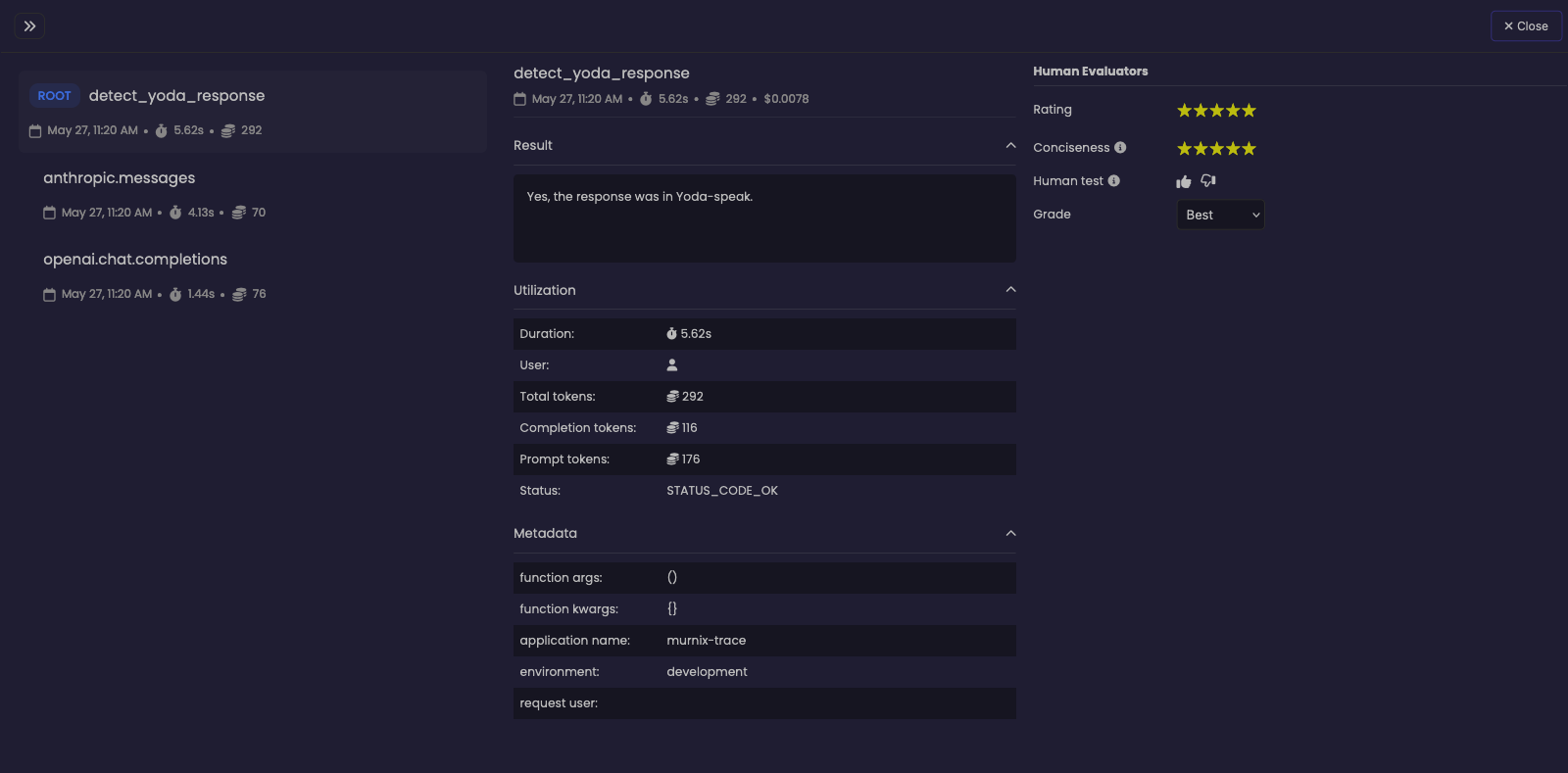
Types of Human Evaluation
- Boolean Evaluation: Allows developers to assess whether the LLM performed as expected based on predefined criteria, with responses limited to true or false.
- List Evaluation: Enables developers to create a list of predefined options for grading LLM performance, providing more flexibility in evaluation criteria.
- Number Range Evaluation: Allows developers to assign a numerical score to rate the performance of the LLM on a scale from 1 to 5, facilitating more granular assessment.
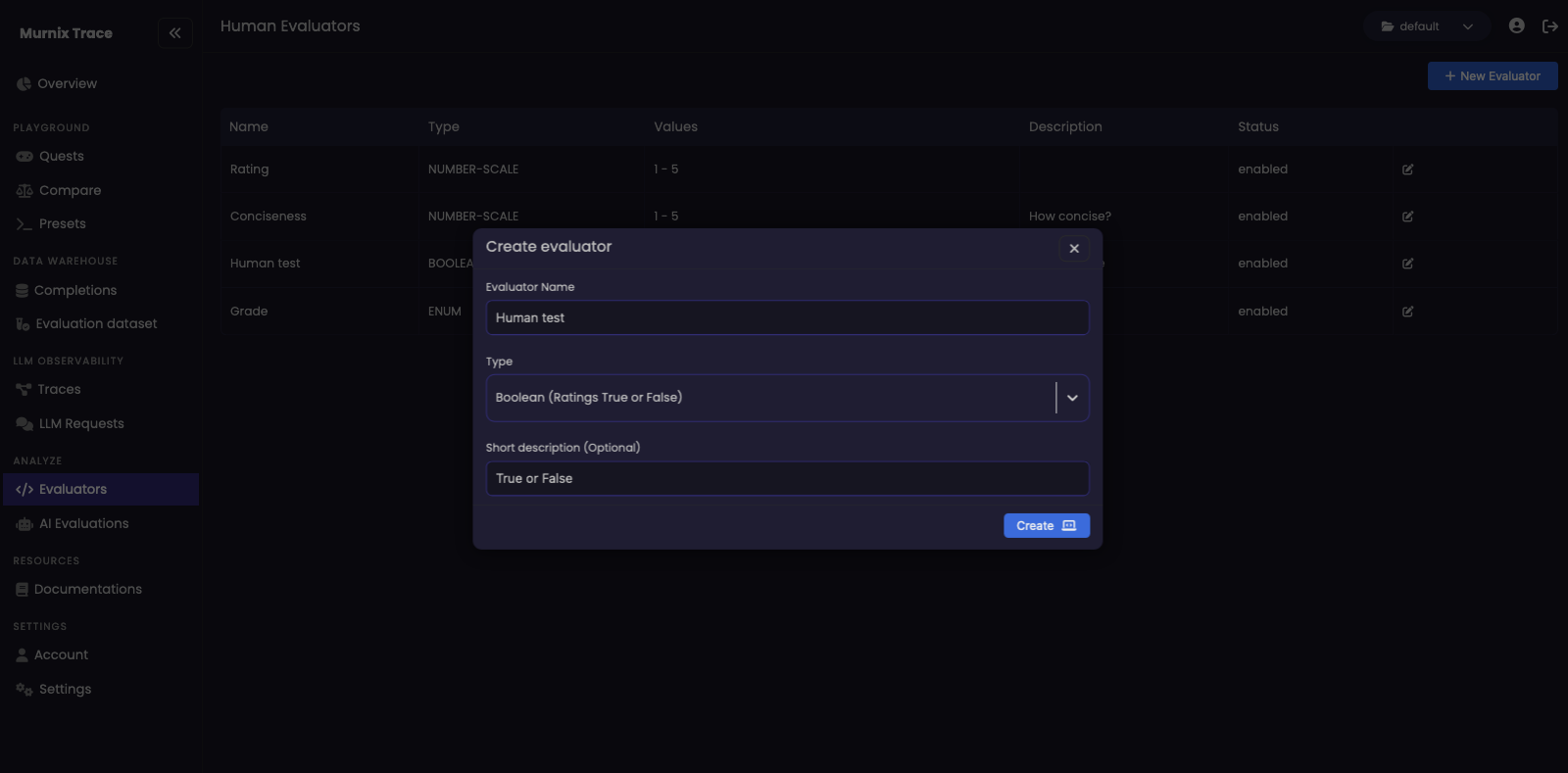
Evaluate